This August, VLDB 2024 will be in Guangzhou, China!
Penn will again be well-represented, with 3 papers in the Research Track:
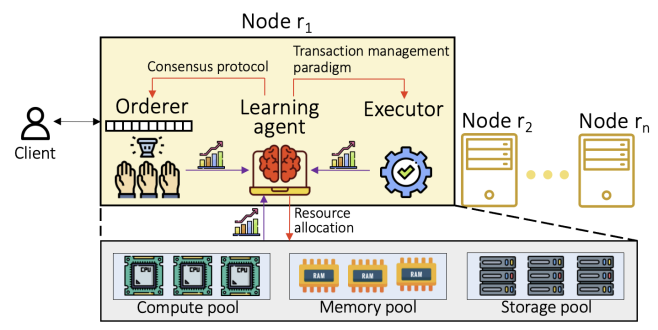
In Towards Full Stack Adaptivity in Permissioned Blockchains, PhD student Chenyuan Wu, postdoc alumnus Mohammad Javad Amiri (Stony Brook University), undergrad student Haoyun Qin (Class of 2025), PhD student Bhavana Mehta, and Profs. Ryan Marcus and Boon Thau Loo study the problem of supporting a (virtual) distributed database with untrusted components — using a learning-based approach. This paper articulates a vision for a learning-based untrustworthy distributed database. We focus on permissioned blockchain systems as an emerging instance of untrustworthy distributed databases and argue that as novel smart contracts, modern hardware, and new cloud platforms arise, future-proof permissioned blockchain systems need to be designed with full-stack adaptivity in mind. At the application level, a future-proof system must adaptively learn the best-performing transaction processing paradigm and quickly adapt to new hardware and unanticipated workload changes on the fly. Likewise, the Byzantine consensus layer must dynamically adjust itself to the workloads, faulty conditions, and network configuration while maintaining compatibility with the transaction processing paradigm. At the infrastructure level, cloud providers must enable cross-layer adaptation, which identifies performance bottlenecks and possible attacks, and determines at runtime the degree of resource disaggregation that best meets application requirements. Within this vision of the future, the paper outlines several research challenges together with some preliminary approaches.
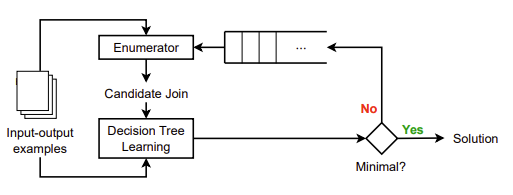
In Relational Query Synthesis ⋈︁ Decision Tree Learning, PhD student Aaditya Naik, PhD alumnus Aalok Thakkar (Ashoka University), PhD student Adam Stein, and Profs. Rajeev Alur and Mayur Naik address the problem of supporting synthesis of SQL queries and consider its interaction with machine learning. They study the problem of synthesizing select-project-join (SPJ) queries from input-output examples. Search-based synthesis techniques are suited to synthesizing projections and joins by navigating the network of relational tables but require additional supervision for synthesizing comparison predicates. On the other hand, decision tree learning techniques are suited to synthesizing comparison predicates when the input database can be summarized as a single labelled relational table. In this paper, they adapt and interleave methods from the domains of relational query synthesis and decision tree learning, and present an end-to-end framework for synthesizing relational queries with categorical and numerical comparison predicates. Their technique guarantees the completeness of the synthesis procedure and strongly encourages minimality of the synthesized program. They present Libra, an implementation of this technique and evaluate it on a benchmark suite of 1,475 instances of queries over 159 databases with multiple tables. Libra solves 1,361 of these instances in an average of 59 seconds per instance. It outperforms state-of-the-art program synthesis tools Scythe and PatSQL in terms of both the running time and the quality of the synthesized programs.
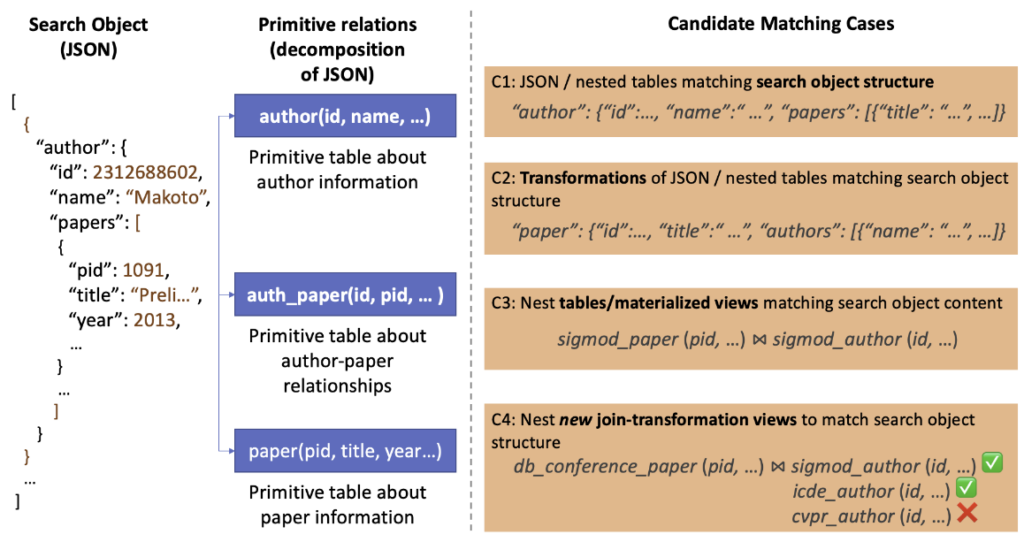
In Searching Data Lakes for Nested and Joined Data, PhD alumnus Yi Zhang (AWS) and undergrad alumnus Peter Chen (PhD student at MIT) and Prof. Zachary Ives consider how to perform search for hierarchical (JSON, Pandas dataframe) or joined data, within a data lake of data that has been indexed in first-normal-form. Exploratory data science is driving new data management platforms that assist data scientists with common tasks, such as the integration and wrangling steps required to assemble training datasets. Such tools take the data scientists’ work-in-progress data as a search object (table or JSON), and find relevant supplementary data from an organizational data lake, which can be unioned or joined with the current data – adding instances or features. Existing data lake search tools seek to find single, relational tables at a time — to match or join with a search table. Yet many data science applications revolve around finding matches to hierarchical data, which can only be matched by creating views simultaneously joining and transforming several tables in the data lake. In this paper, they extend the Juneau data lake search system to search for this broader class of matches at scale. Their contribution is a general framework for efficiently merging ranked results, leveraging novel techniques for indexing and sketching, and incorporating existing single-table search techniques and ranking functions. They experimentally validate the benefits of their methods and their broad applicability using real data from data science computational notebooks. Their results indicate that, with respect to different ranking functions, their approach can return the optimal set of views up to 4.81x faster and 43% more related compared to heuristics baselines, and increase the data domain coverage by up to 28%. As a case study to show the usability of their augmentation to data science downstream tasks, their methods can reduce the regression error by up to 6.63%, and improve the classification accuracy by up to 19.5% for ML models.


