The Penn Database and Data Systems Group is well-represented at SIGMOD 2025!
At the aiDM workshop, co-chaired by our own Ryan Marcus, there are two papers:
- SERAG: Self-Evolving RAG System for Query Optimization, Hanwen Liu, Qihan Zhang, University of Southern California, Ryan Marcus, University of Pennsylvania, Ibrahim Sabek, University of Southern California.
- Data-driven Adaptive Processing of Streaming ML Queries, by Phillip Hilliard, Rajeev Alur, Zachary Ives, University of Pennsylvania. This paper describes an adaptive query processing technique targeted at stream systems that incorporate machine learning components. When given a set of alternative machine learning models with different cost-accuracy trade-offs, it dynamically chooses the model that maximizes accuracy while satisfying a budgetary or quality-of-service constraint.
At the main SIGMOD conference, the following papers will be presented.
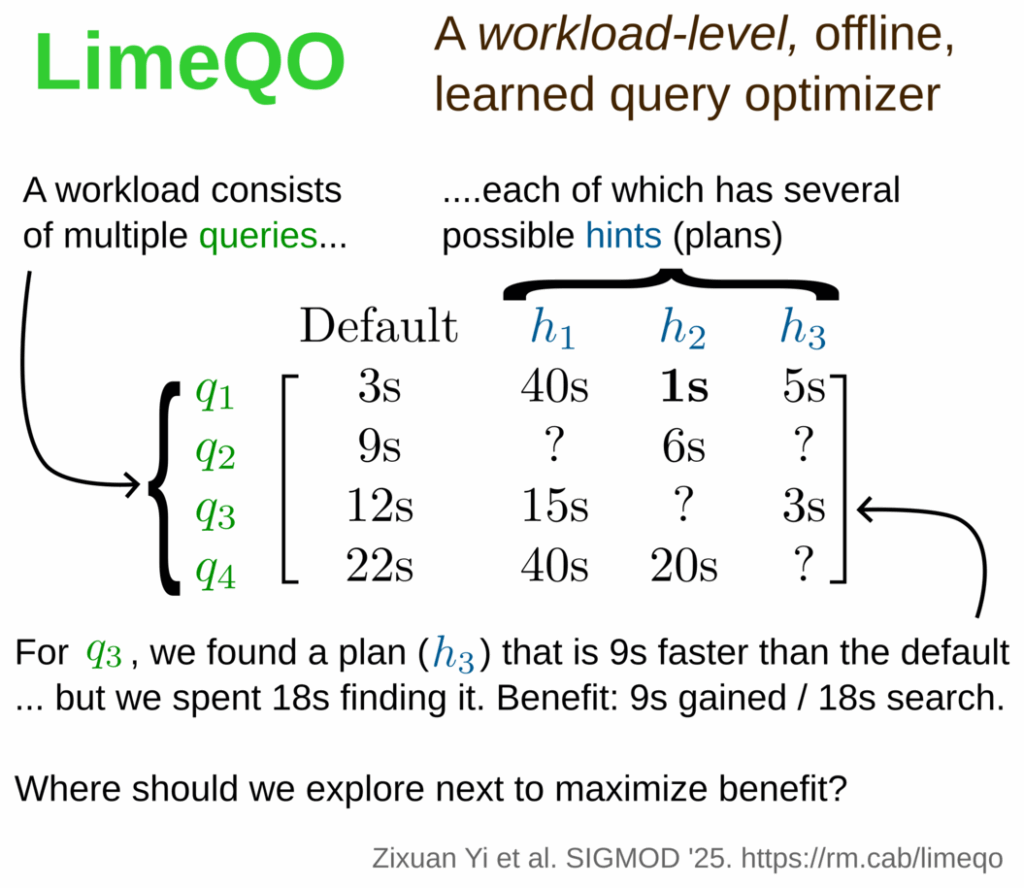
Low Rank Learning for Offline Query Optimization
Zixuan Yi (University of Pennsylvania)*; Yao Tian (The Hong Kong University of Science and Technology); Zack Ives (University of Pennsylvania); Ryan Marcus (University of Pennsylvania).
This paper develops a novel technique based on low-rank matrix factorization, which allows a query optimizer to predict which query processing strategies will be useful for one query, based on performance of other queries.
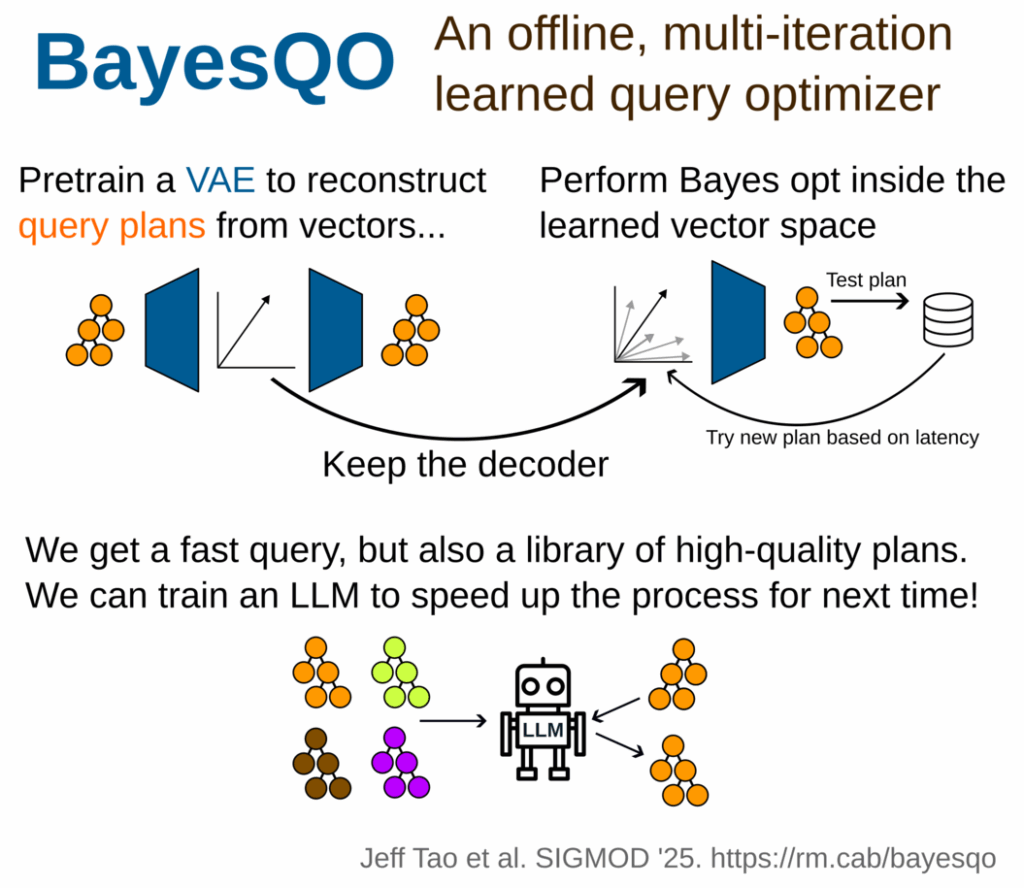
Learned Offline Query Planning via Bayesian Optimization
Jeffrey Tao; Natalie Maus; Haydn Jones; Yimeng Zeng; Jacob Gardner; Ryan Marcus.
Targeting queries that are going to be executed thousands of times, we propose an offline query optimizer that searches a wide variety of plans and incorporates query execution as a primitive. Our offline query optimizer combines variational auto-encoders with Bayesian optimization to find optimized plans for a given query.
- SHARQ: Explainability Framework for Association Rules on Relational Data
Hadar Ben Efraim (Bar-Ilan University); Susan B Davidson (University of Pennsylvania); Amit Somech (Bar-Ilan University)*. Association rules are an important technique for gaining insights over large relational datasets. However, it is difficult to explain the relative importance of data elements with respect to the rules in which they appear. This paper develops a measure of an element’s contribution to a set of association rules based on Shapley values, denoted SHARQ (ShApley Rules Quantification). - Physical Visualization Design: Decoupling Interface and System Design
Yiru Chen (Columbia University)*; Xupeng Li (Columbia University); Jeffrey Tao (University of Pennsylvania); Alana Ramjit (Cornell Tech); Ravi Netravali (Princeton University); Subrata Mitra (Adobe Research); Aditya Parameswaran (University of California, Berkeley); Javad Ghaderi (Columbia University); Dan Rubenstein (Columbia University); Eugene Wu (Columbia University) - CARINA: An Efficient CXL-Oriented Embedding Serving System for Recommendation Models
Peiqi Yin (The Chinese University of Hong Kong)*; Qihui Zhou (CUHK); Xiao Yan (Centre for Perceptual and Interactive Intelligence (CPII) ); Chao Wang (The Chinese University of Hong Kong); Eric Lo (Chinese University of Hong Kong); Changji Li (CUHK); Lan Lu (University of Pennsylvania ); Hua Fan (Alibaba Cloud); Wenchao Zhou (Alibaba Group); Ming-Chang YANG (The Chinese University of Hong Kong); James Cheng (CUHK)
At the demo sessions:

ScaleLLM: A technique for scalable LLM-augmented data systems.
Paul Loh (University of Pennsylvania); Ashwin Alaparthi (University of Pennsylvania); Ryan Marcus (University of Pennsylvania);
- PY-SHARQ: A Holistic Python Library for Explaining Association Rules on Relational Data
Hadar Ben-Efraim (Bar-Ilan University), Susan Davidson (University of Pennsylvania), Amit Somech (Bar-Ilan University)
We hope to see you in Berlin!


